Problem Setup
For simplicity, let us first consider a one-step decision-making process (also known as a contextual bandit).
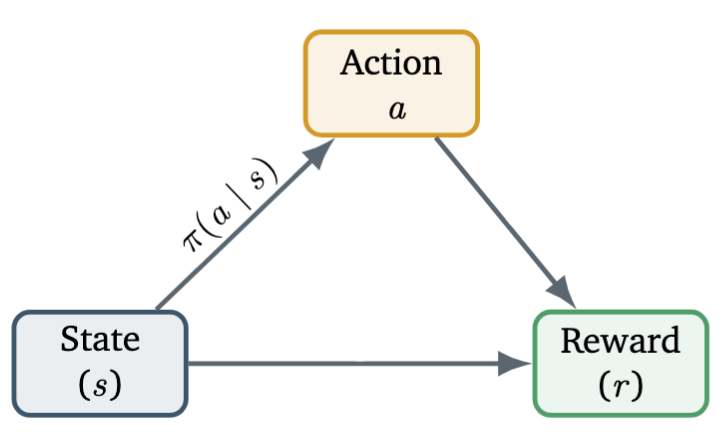
We define the following notions:
- Let be the state vector of the environment, describing the current situation or configuration the agent observes (for example, the position of a robot, or the market condition in trading).
- Let be the action taken by the agent — a decision or move that affects the environment (e.g., moving left/right, buying/selling).
- Let denote the reward function, which assigns a numerical score to each action–state pair, indicating how desirable the action is when taken in that state.
The agent’s behavior is characterized by a policy, represented as a conditional probability distribution which specifies the probability of selecting each possible action given the current state .
The objective is to learn an optimal policy that maximizes the expected reward under the environment’s state distribution. Formally, we define the performance of a policy as
which can equivalently be written as a joint expectation:
where denotes the (unknown) distribution of states in the environment, and
is the joint distribution of states and actions induced by the policy .
In practice, the state distribution is rarely known in closed form; instead, we have access to a finite set of samples drawn from , typically obtained from interaction with the environment or an existing dataset.
So far, we have
Policy Gradient
In practice, the policy is parameterized by a differentiable function. The gradient of the expected reward is:
(Used the log-derivative trick: .)
Reward Baseline
For any policy , we can derive the following identity:
Then, we have
Hence, by the linearity of expectation, we can subtract any function independent of from the reward without changing the policy gradient:
where is any function independent of .
Choosing gives the advantage function:
A positive means the action performs above average.
So far, we have the policy gradient expressed as
On-Policy Estimation
Given data with and ,
with .
Gradient ascent update (REINFORCE):
Intuitively:
- : increase ;
- : decrease it.
Connection to Weighted MLE
If data are fixed, the policy gradient equals the gradient of the -weighted log-likelihood.
Let’s consider the following log-likelihood function:
Thus, policy optimization ≈ adaptive MLE with dynamic weights .
Off-Policy Estimation (Importance Sampling)
If data are drawn from a behavior policy , using importance sampling, we have:
where
and the normalization factor is often taken as .
Proximal Policy Optimization (PPO)
Proximal Point Method
Starting from , iterate:
where measures the deviation between parameters (e.g., squared distance or KL divergence).
This forms the basis for proximal methods.
Proximal Gradient Descent
Approximate by its first-order Taylor expansion:
Then, since is independent of the optimization variable , the update becomes:
Preconditioning Gradient Descent
Consider a quadratic proximal penalty:
where is a positive definite matrix, chosen by user.
Then the update has a closed-form solution:
This is known as preconditioned gradient descent.
Remark. Assume we use gradient descent to solve the inner loops of proximal methods. The difference from vanilla gradient descent then lies in how the reference point is updated. To see this, let us consider the following generic update rule
The proximal point framework interpolates between fast-updating methods (gradient descent) and slower, more implicit schemes, depending on how the reference point evolves.
- : proximal gradient descent
- : inner-loop updates
- EMA of past iterates → smoother, more stable updates
Proximal Policy Optimization (PPO)
Applying the proximal framework to policy optimization with importance sampling:
Derivation:
We have the original formula
From off-policy estimation, we have
Taking integration, we have
Substitute above to the original formula, we get the final result.
The penalty term is usually the KL divergence:
Clipping Objective
PPO further introduces a clipping function:
where and
Different choices of penalty and clipping function yield different stability–efficiency tradeoffs.
GRPO
GRPO Basic
In GRPO case, we change the advantage function into group-relative advantage.
For a given state , the policy takes different action .
We define the following notations:
- Let , which denotes the reward for action .
- Let denote the group-reward for state .
- Let and denote the mean and standard deviation of the gorup-reward .
We define the advantage function for action as follows:
GRPO in LLMs
In LLMs setting, we define the following notation
- The user query .
- The model response
- Response probability
- Response reward